Nozioni su Awk
Informazioni introduttive
Se nella distribuzione in uso provassimo a impartire il comando grep awk -r /etc/* potremo osservare come, al di là di percorsi e/o file non accessibili da utente normale (anche se nessuno vieta di impartire il comando con le credenziali di amministratore in quanto assolutamente “innocuo”), verranno restituiti un certo numero di risultati. Se si è inclini all’utilizzo di script bash probabilmente in qualche occasione si è già avuto modo di incontrare questo strano nome: awk chiedendosi, anche distrattamente, quale funzione potesse svolgere.
Non si tratta, come si potrebbe essere indotti a pensare, di un comando con un unico scopo, ma è l’eseguibile dell’interprete del linguaggio di programmazione omonimo. Un linguaggio interpretato molto esteso, fornito di costrutti e funzioni built-in comuni a molti linguaggi di programmazione: variabili, aritmetica, array, cicli, funzioni etc fanno di Awk un linguaggio di scansione e elaborazione testi molto potente. Chi ha un po’ di dimestichezza nell’uso del programma grep (man grep) potrà trovare familiari alcuni aspetti di approccio nell’uso di Awk.
Prima di entrare nel vivo è il caso di ricordare che il nome AWK, deriva dalle iniziali dei cognomi dei suoi inventori: Aho Alfred, Weinberger Peter e Kernighan Brian. Nato nel 1977, di Awk ne è stata rilasciata nel 1985 una nuova versione che permetteva all’utente di definire nuove funzioni. Con il tempo sono nate diverse varianti quali mawk per una implementazione più performante di Awk, o nawk (NewAwk) una nuova versione di Awk ad opera degli stessi autori. Discorso a parte merita gawk (GNU Awk) i cui sviluppatori hanno esteso la versione originale inserendo il supporto all’internazionalizzazione, nuove funzioni e possibilità per gli utenti di inserire propri “plugin” al fine di estenderne le funzionalità a seconda dell’occorrenza. Esistono altre varianti come jawk (implementazione Awk in Java), bwk (implementazione Brian W. Kernighan) etc. In questo contesto si farà riferimento a awk, ma in una distribuzione GNU/Linux implicitamente significa riferirsi a gawk poiché awk è un link a esso.
Nel prosieguo verranno analizzate le caratteristiche principali di Awk anche con alcuni esempi: l’obiettivo sarà arrivare a capire, ad esempio, perché la riga awk {print $3, $2} tabella stampi la terza e la seconda colonna di una tabella nell’ordine indicato o perché awk ‘$2 ∼ /A B C/’ nome_file stampi tutte le linee di ingresso con una A, B, o C nel secondo campo così come la riga awk ‘$1 != prec { print; prec = $1 }’ nome_file stampi solo le righe nelle quali il primo campo della riga attuale è diverso dal primo campo della riga precedente e sarà diverso dal primo campo della riga successiva.
Com’è strutturato Awk?
Un programma Awk è in genere costituito da una serie di comandi nella forma pattern {azione}, dove pattern identifica una data sequenza da cercare nei dati in ingresso mentre azione descrive cosa eseguire sulla corrispondenza trovata. Il pattern non è obbligatorio e, nel qual caso fosse mancante, l’azione verrà intrapresa per ogni riga, in questo caso il programma inizierà con { e terminerà con }. Anche azione può essere assente, ma non se lo è già il pattern, nel qual caso la riga corrispondente viene semplicemente stampata sull’output. Una riga viene scartata se in essa non viene trovata alcuna corrispondenza.
Un programma Awk effettua la lettura dell’input riga dopo riga. Ogni singolo record (riga) è suddiviso in campi: ogni singolo campo viene memorizzato all’interno di variabili posizionali $n con n=1,2,…,NF alle quali, poi, è possibile accedere con le usuali modalità degli script.
Ma come fa Awk a “capire” quando termina una riga e come i campi devono, o possono, essere suddivisi? Vengono utilizzate delle variabili interne che forniscono le informazioni e controllano il comportamento dell’interprete. In base a quanto fin qui riportato possiamo identificare le seguenti variabili (lista non esaustiva):
- RS – Record Separator, variabile che determina il separatore di righe (una riga è un record). Di default è un carattere di newline \n;
- NF – Number of Field, ovvero il numero di campi in cui viene identificato il record (la riga) corrente ($1, $2, …, $NF);
- FS – Acronimo di Field Separator è la variabile deputata all’identificazione dei campi in ingresso: di default è il carattere di spazio ma si può impostare a seconda delle esigenze;
- NR – Number of Record, è una variabile aggiornata ad un valore coincidente con il numero di righe (record) fino a quel momento lette.
Awk può quindi identificare righe e campi attraverso specifici caratteri impostati attraverso le variabili d’ambiente. Analoghe considerazioni per il comportamento del programma nella stampa dell’output, ad esempio:
- OFS – Output Field Separator, definisce il separatore da utilizzare nella stampa dei campi di uscita con l’istruzione print: predefinito è uno spazio;
- ORS – Output Record Separator, definisce il separatore dei record (righe) in uscita, di default è un newline \n.
Esempi d’uso
Il comando ls (man ls) con l’opzione -l elenca una lista estesa delle proprietà dei file con i campi separati da uno spazio. Allora la pipe ls -l | awk ‘{print $5}’ stamperà il 5° campo dell’output di ls. Poiché il 5° campo di ls -l è la dimensione del file, il risultato sarà un elenco della dimensione dei file, uno per ogni riga (ricordando che di default la variabile d’ambiente ORS è un newline).
Il comando history (man history) fornisce lo storico dei comandi (su due campi: numero progressivo e tipo di comando) impartiti nella shell e salvati nel file .bash_history presente nella home utente. Se volessimo elencare i 6 comandi più utilizzati e memorizzati nella history come fare? In output dobbiamo stampare solo il secondo campo di quanto fornito da history pertanto la pipe:
history | awk '{print $2}' | sort | uniq -c | sort -rn | head -n 6
sarà la soluzione! Infatti l’output del comando history verrà inviato all’ingresso di awk che stamperà, per ogni riga, solo il secondo campo memorizzato nella variabile posizionale $2 ($1 memorizza il numero progressivo, il primo campo del flusso di history che nello scenario prospettato non è di nostro interesse). Il resto della linea vede sort ordinare alfabeticamente l’output di awk e uniq -c raggruppare tutte le righe uguali contandole al tempo stesso. A questo punto non resta che ordinare l’output in maniera inversa, dall’occorrenza maggiore a quella minore e non più alfabeticamente, e ciò è possibile con le opzioni -r e -n di sort (man sort per approfondimenti). A questo punto è sufficiente filtrare solo le prime 6 righe con head (man head) per ottenere il risultato desiderato.
Altro esempio:
awk -F”|” ‘substr($5, 7, 2) > 55 && substr($5, 7, 2) < 62’ Impiegati
Con questa riga, in un ipotetico file di testo di nome Impiegati, estraiamo tutto il personale nato tra il 1956 e il 1962. La coppia && indica un and logico. La prima parte, -F”|”, cambia la variabile d’ambiente FS definendo come nuovo separatore di campi il carattere pipe |, questo ipotizzando che le colonne siano separate dal suddetto carattere. A questo punto usando la funzione built-in substr(s,i,n) si esaminano i 2 caratteri, a partire dal 7° incluso, del 5° campo: in sostanza se la data di nascita del 5° campo è riportata come 01/09/69 verrà verificato se la stringa 69 rientra o meno nel range.
La sintassi di Awk
Awk prevede nei comandi forme simili ai più comuni linguaggi di programmazione. Di seguito in rassegna qualche esempio pratico e applicativo:
- if (pattern) {azione} else {azione};
- while (pattern) {azione};
- do {azione} while {pattern};
- for (inizializzazione;pattern;incremento) {azione};
- switch (pattern) {
case valore|regexp : azione
…
default: azione
}
Per il ciclo for è possibile utilizzare una seconda forma:
for (var in array) {azione}
È possibile definire proprie funzioni (ricorsive e non) utilizzando la parola chiave function con la sintassi:
function nome_funzione (arg1,arg2,arg3,...,argN)
{
comandi;
[...]
return valore;
}
Alle funzioni create ad-hoc, a seconda delle proprie esigenze, si possono affiancare un’altra serie di funzioni built-in alcune delle quali possono manipolare campi e record (man gawk per l’elenco completo). Ad esempio per scrivere la tipica funzione ricorsiva per il calcolo del fattoriale:
function fattoriale(numero)
{
if (numero <= 1)
{
return(1)
}
else
{
return (numero * fattoriale(n-1))
}
}
quindi richiamarla all’occorrenza in una coppia pattern-azione oppure da un’altra funzione, ad esempio con:
$3 ~ /^[0-9]+$/
{
m=fattoriale($3)
}
Per chi non li conoscesse tra breve saranno chiari i simboli che si hanno nella prima riga. Si osservi come la sintassi per la definizione delle variabili in Awk è nel formato classico Nome=Valore: non c’è la necessità di definirle prima, ma si possono usare direttamente all’occorrenza. In più, l’input verso Awk e l’output da Awk possono essere rediretti in una modalità pressoché identica a quella della shell bash utilizzando gli operatori < e > rispettivamente per la redirezione dell’input e dell’output: è sufficiente far seguire gli operatori dal percorso del file dal quale si vuole leggere l’input o sul quale si vuole scrivere l’output.
Le espressioni regolari in Awk
La riga:
awk '/^UUID/ {print $1;}' /etc/fstab
fornirà in uscita l’elenco degli UUID (Universal Unique IDentifier) presenti nel file fstab che, qui si vuole ricordare, è caratterizzato da 6 campi separati da uno spazio, e in questo caso viene stampato solo il primo che coincide con il pattern iniziale UUID. Notare la presenza del carattere ^ che ci introduce nelle espressioni regolari supportate da Awk. In generale se del pattern /espressione regolare/ viene trovata una corrispondenza con il record in ingresso, è eseguita la corrispondente azione che nello specifico è la stampa del 1° campo del record.
Altro esempio:
ls -l | awk 'NR!=1 && !/^d/ {print $NF}'
L’output di ls viene inviato a awk e le righe che non iniziano con una d (sequenza !/^d/) e sono diverse dalla prima riga (condizione NR!=1) verranno stampate, pertanto in output si otterrà solo l’elenco dei file (link compresi) del percorso indicato a ls e verranno escluse le directory. La prima riga non viene considerata poiché sarà del tipo totale <numero> ad indicare il numero di blocchi totali del disco allocati per tutti i file presenti nel percorso elencato, numero di blocchi che è possibile conoscere per ogni singolo file/cartella con ls -ls e la dimensione allocata con ls -lh in modalità “human readable”.
Ora la riga riportata nella funzione fattoriale dovrebbe essere più chiara, ancora di più se si osserva che l’operatore ~ (simbolo tilde ottenibile con Alt Gr+ì) viene utilizzato per il confronto delle stringhe nelle espressioni regolari pertanto $3 ~ /^[0-9]+$/ indica che se il 3° campo del flusso di dati in ingresso coincide con un numero viene richiamata la funzione fattoriale e il risultato assegnato alla variabile m. Si fa presente che la conoscenza delle espressioni regolari estese che è possibile incontrare con l’uso del comando egrep (man egrep) facilita la comprensione poiché è la medesima forma supportata da Awk!
Si immagini una riga del tipo:
rootopts=$(awk '{ if ($1 !~ /^[ \t]*#/ && $2 == "/") { print $4; }}' /etc/mtab)
che si può trovare in un file di configurazione di alcune distribuzioni GNU/Linux (e.g. Fedora). Niente panico! Trattasi di una espansione di comando $(…) della shell bash che assegna alla variabile rootopts il risultato della riga presente all’interno delle parentesi tonde. Ma cosa fa di preciso tale riga? Prima di tutto preleva l’input dal file /etc/mtab (ovvero da /proc/mounts poiché ne è un collegamento simbolico) il cui contenuto è visibile nella figura in basso utilizzando da shell il comando cat /etc/mtab.
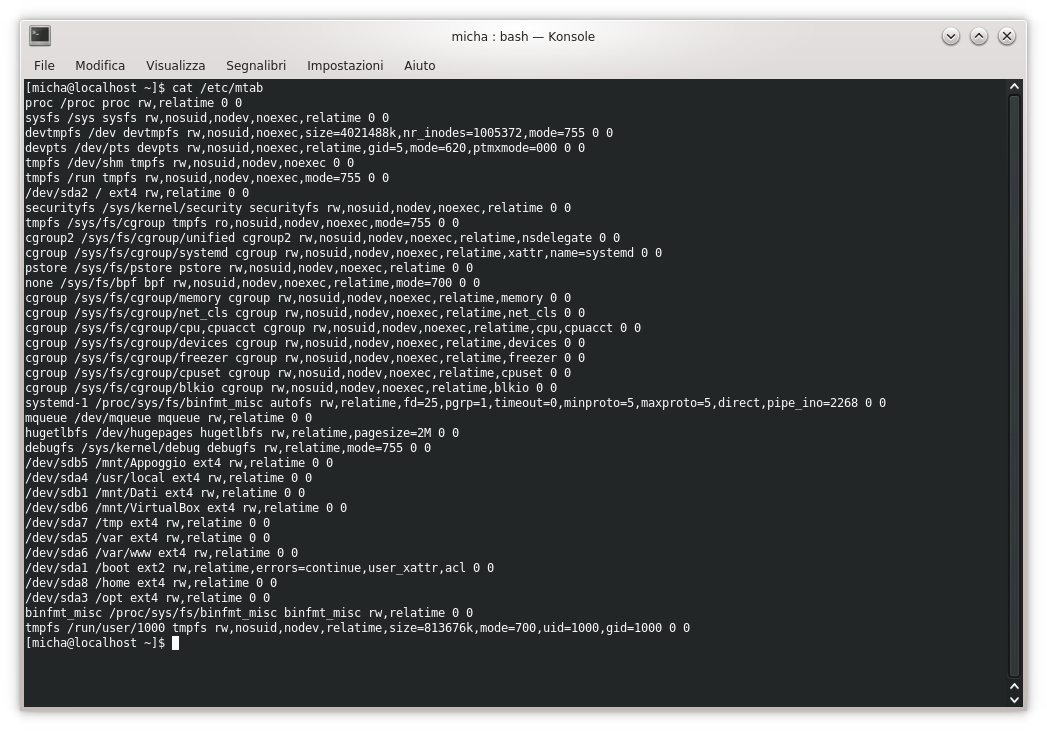
Uscita del comando “cat /etc/mtab”
Se l’espressione nell’if è verificata viene stampato, quindi assegnato alla variabile rootopts, il 4° campo di mtab che coincide con le opzioni di montaggio del filesystem. L’espressione nel comando if sarà vera, e quindi verrà eseguita l’azione corrispondente, se il primo campo dei record in input è diverso da spazi bianchi e il secondo campo è uguale ad uno slash.
Non sempre una riga è sufficiente!
Quando si ha la necessità di un programma con funzioni un po’ più complesse, potrebbe essere opportuno fare riferimento ad un file. Ad esempio:
BEGIN {print "Nome File \t","Proprietario \t","Gruppo"}
{print $9, " \t", $3, " \t", $4}
END {print " - Analisi terminata - "}
Queste tre sole righe permettono di definire un’altra proprietà di un programma Awk, l’impiego di due pattern speciali: BEGIN la cui esecuzione avviene prima dell’analisi della prima riga del flusso in ingresso, pertanto può essere utilizzato per delle intestazioni, come in questo esempio, oppure per inizializzare variabili e/o nuove assegnazioni a variabili d’ambiente dell’interprete. Se non si rendono necessarie queste impostazioni iniziali BEGIN può essere omesso, ma vi sono applicazioni che vedono BEGIN contenere l’intero programma Awk!
Il parametro speciale END è invece eseguito dopo l’ultima riga del flusso in ingresso, all’uscita del programma, pertanto può essere utilizzato per stampare i risultati dell’elaborazione, ma anche qui, se durante l’elaborazione vengono stampati i risultati necessari, può essere omesso.
Chi conosce il linguaggio C non avrà difficoltà alcuna nell’uso della printf in Awk. La forma più semplice vede la sintassi printf (format, arg1, arg2….) laddove format è una stringa o una variabile il cui valore può contenere sequenze di escape come \t per la tabulazione, \n per il newline etc. La potenza di printf è negli specificatori di formato che iniziano con il carattere %: ad esempio %d per i numeri interi, %o per i numeri in ottale, %s per le stringhe, %x per i numeri in esadecimale e infine %% per il significato letterale di %.
Ma cosa fanno di preciso le tre righe? Le righe BEGIN e END sono state descritte, il cuore del programma è la seconda riga nella quale viene comandata la stampa del 9°, del 3° e del 4° campo del flusso in ingresso.
Se le tre righe vengono salvate in un file Esempio.awk all’interno di una cartella e viene impartito il comando
ls -l | gawk -f Esempio.awk
verranno elencati gli elementi presenti nella cartella, l’associato proprietario e gruppo di appartenenza.
Finora esempi un po’ semplici, per questo motivo nel seguito si potrà ricopiare su un file – ad esempio di nome NumeriLotto.awk da salvare in una cartella qualsiasi – il sorgente di un semplice programma che genera numeri casuali da 1 a 90 …da giocare al lotto! Il sorgente è commentato – i commenti in Awk iniziano con # – e per l’esecuzione è sufficiente salvare il file in una cartella e lanciarlo con gawk -f NumeriLotto.awk e …buona fortuna!
BEGIN {
# Inizializziamo la funzione per generare numeri casuali
# Sezione "Numeric Functions" manuale online, man gawk.
srand();
# Ipotizziamo di volere due numeri casuali per giocare un ambo
# su tutte le ruote. Qualora volessimo giocare, ad esempio, un
# terno sulla nostra ruota preferita possiamo impostare la
# variabile NUMERI=3. Analogamente per 4 e più numeri.
NUMERI=2;
# Nel gioco del lotto il numero 1 è il più piccolo...
NUMERO_MIN=1;
# ...mentre il 90 è il numero più grande
NUMERO_MAX=90;
# Impostiamo la variabile DATI a 0 al fine di inizializzarla.
# La variabile DATI terrà il conto della quantità di numeri
# fino a quel momento forniti dal programma.
DATI=0;
# Eseguiamo il loop while fino a che i numero forniti dal
# programma siano minori dei numeri richiesti. L'uguaglianza
# non può essere utilizzata perché il conteggio della
# variabile DATI inizia da 0 e quindi verrebbe fornito un
# numero in più rispetto a quelli richiesti.
while (DATI &amp;amp;amp;amp;amp;amp;amp;amp;lt; NUMERI) {
# Generiamo un numero casuale compreso tra 1 e 90
r=int(((rand() *(1+NUMERO_MAX-NUMERO_MIN))+NUMERO_MIN));
# Verifichiamo se l'array contiene già il numero.
# In questa sede facciamo solo presente che il
# concetto di array in Awk è differente dagli
# altri linguaggi di programmazione. In Awk
# tutti gli array sono associativi: capiremo
# nel prossimo appuntamento il significato.
if (array[r] == 0) {
# Se il numero non è presente allora lo memorizziamo
# nell'array e incrementiamo tanto la variabile DATI
# quanto l'array.
DATI++;
array[r]++;
}
}
# Ora è tempo di stampare il risultato affinché li si possa giocare
# e magari vincere. :-)
# Utilizziamo il for nella forma nota anche negli script shell per
# riprendere il contenuto dell'array e passare alla stampa con printf.
for (i=NUMERO_MIN;i<=NUMERO_MAX;i++) {
# Se presente nell'array allora passa alla stampa
if (array[i]) {
# Poiché siamo in presenza di numeri interi allora
# utilizziamo lo specificatore di formato %d.
printf("%d ",i);
}
}
printf("\n");
exit;
}
Gli esempi riportati sono principalmente didattici e, come ogni problema, diverse possono essere le soluzioni per il raggiungimento del target. Una volta raggiunta una certa dimestichezza (e questo vale per e con qualsiasi linguaggio) ciò che non si dovrà mai dimenticare è la massima degli “illuminati”:
Non si dovrebbe mai usare il linguaggio C se puoi ottenere il risultato con uno script. Non si dovrebbe mai usare uno script se il risultato è raggiungibile con Awk. Mai usare Awk se puoi farlo con sed (man sed) e, infine, mai usare sed se puoi farlo con grep (man grep)!.
Possibili campi applicativi
È noto come, in linea generale e in funzione dell’applicazione, un programma interpretato presenti minori performance rispetto ad un compilato, ma questo non impedisce al programma interpretato di essere impiegato in determinati campi soprattutto quando il tempo di esecuzione è paragonabile, se non inferiore, al “cugino” compilato. In quest’ottica Awk potrebbe essere proficuamente e convenientemente utilizzato per applicazioni come (lista non esaustiva):
- Gestione dei campi di un database;
- Generazione di report;
- Indicizzazione e adeguamento del file per analisi successive;
- Ordinamento dei dati;
- Creare grafici con caratteri ASCII fino a vere immagini bitmap.
Illustrando nel seguito alcune di queste applicazioni si cercherà al tempo stesso di fornire ulteriori nozioni su Awk.
Una prima applicazione
Quando si lavora con file di testo, un tipo e numero di operazioni potrebbero essere necessarie prima che il file possa essere inviato ad una elaborazione successiva: ad esempio cambiare certi pattern o singoli caratteri. Tali operazioni possono essere svolte da qualsiasi tool scritto nei vari linguaggi di programmazione, come gli onnipresenti C e C++, ma se è possibile svolgerle con poche righe e con un linguaggio, potremmo dire “dedicato” a questi compiti, senza necessità alcuna di passare attraverso compilazioni o meta-compilazioni, sarebbe meglio. È stato fin qui compreso come di Awk sia un linguaggio interpretato facilmente integrabile con gli script shell e utilizzabile in diversi ambiti. In quest’ottica, allora, perché non utilizzarlo anche per compiti più impegnativi e difficili? Il motivo, al di là del fatto che non può sostituire in toto altri linguaggi, è puramente prestazionale: è noto come uno script interpretato risulti essere generalmente più lento di un programma compilato.
Acronimo di Comma-Separated Values (valori separati da virgola) il formato CSV è probabilmente il modo più semplice, “leggero” e immediato per scrivere i dati su un file e estrapolarli da esso in una fase successiva per l’interpretazione. Sebbene il formato CSV dovrebbe avere, implicitamente già dal nome, una formattazione per certi versi standard, ci si può trovara davanti file CSV con diverse “sfumature” con la necessità di specifici cambiamenti al fine di renderlo (eventualmente meglio) utilizzabile successivamente da altri programmi.
Ad esempio alcuni dispositivi di rilevazione (anche in funzione di come vengono programmati) potrebbero fornire in uscita sulla porta USB un output del tipo:
Giorno;Data[aa:mm:gg];Orario;Temp;Umid.Relativa;CO Mon, 15/01/19, 19:38:00;20.96;61.77;7.86 Mon, 15/01/19, 19:39:00;17.41;62.12;7.48 Mon, 15/01/19, 19:40:00,16.12,61.77,7.20 Mon, 15/01/19, 19:41:00,15.80,61.77,7.29 Mon, 15/01/19, 19:42:00,16.12,62.29,7.15 Mon, 15/01/19, 19:43:00,16.12,61.77,7.29 Mon, 15/01/19, 19:44:00,16.12,61.60,7.34 Mon, 15/01/19, 19:45:00,16.12,61.60,7.25 Mon, 15/01/19, 19:46:00,16.45,61.60,7.44 Mon, 15/01/19, 19:47:00,16.12,61.77,7.39 Mon, 15/01/19, 19:48:00,16.45,61.77,7.48 Mon, 15/01/19, 19:49:01,16.45,61.94,7.34 Mon, 15/01/19, 19:50:01,16.77,61.77,7.62 Mon, 15/01/19, 19:51:01,16.45,61.60,7.62 Mon, 15/01/19, 19:52:01,16.45,61.77,7.39 Mon, 15/01/19, 19:53:02,16.45,61.60,7.62 Mon, 15/01/19, 19:54:02,16.45,61.60,7.53 Mon, 15/01/19, 19:55:02,28.38,61.94,7.62 Mon, 15/01/19, 19:56:02,16.45,61.60,7.48 ...
dove si possono leggere i 6 campi riportati sulla prima riga: partendo da sinistra si ha il giorno della settimana, la data, l’orario della rilevazione seguiti dai 3 campi dei valori forniti dai sensori, rispettivamente temperatura (°C), umidità relativa (in %) e la concentrazione di monossido di carbonio (mg/m^3).
Si può pensare di fare degli aggiustamenti in funzione del target. Ad esempio si potrebbero caricare come file CSV i dati in LibreOffice Calc localizzato in Italiano. Si può osservare, però, come vi siano campi separati dal carattere “,” e dal carattere “;” pertanto occorre rendere uniforme il file in termini di separatori da utilizzare qualora si volesse, ad esempio, tirare fuori un grafico delle rilevazioni mensili:
- Cambiare la rappresentazione decimale da quella anglosassone, con il punto, a quella in uso in Italia (ma non solo) con la virgola;
- Cambiare il carattere da “,” in “;” affinché il separatore di campo (colonne) sia congruente in tutto il file. Così facendo è evidente come il file CSV risulti non rispetti il proprio standard, ma permette a LibreOffice Calc nel pannello Opzione di sillabazione all’atto del caricamento di optare solo per Punto e virgola e di fargli visualizzare il file senza problemi con il giusto numero di campi correttamente incolonnati.
In sostanza l’obiettivo finale sarà ottenere un file del tipo:
Giorno;Data[aa:mm:gg];Orario;Temperatura;Umid.Relativa;CO Mon;15/01/19;19:38:00;20,96;61,77;7,86 Mon;15/01/19;19:39:00;17,41;62,12;7,48 Mon;15/01/19;19:40:00;16,12;61,77;7,20 Mon;15/01/19;19:41:00;15,80;61,77;7,29 Mon;15/01/19;19:42:00;16,12;62,29;7,15 Mon;15/01/19;19:43:00;16,12;61,77;7,29 Mon;15/01/19;19:44:00;16,12;61,60;7,34 Mon;15/01/19;19:45:00;16,12;61,60;7,25 Mon;15/01/19;19:46:00;16,45;61,60;7,44 Mon;15/01/19;19:47:00;16,12;61,77;7,39 Mon;15/01/19;19:48:00;16,45;61,77;7,48 Mon;15/01/19;19:49:01;16,45;61,94;7,34 Mon;15/01/19;19:50:01;16,77;61,77;7,62 Mon;15/01/19;19:51:01;16,45;61,60;7,62 Mon;15/01/19;19:52:01;16,45;61,77;7,39 Mon;15/01/19;19:53:02;16,45;61,60;7,62 Mon;15/01/19;19:54:02;16,45;61,60;7,53 Mon;15/01/19;19:55:02;28,38;61,94;7,62 Mon;15/01/19;19:56:02;16,45;61,60;7,48 ...
Va da se che non è possibile modificare a mano ogni singola riga: si immagini infatti che le righe riportate siano una delle migliaia di uno storico di rilevazioni in 1 mese. Come procedere?
Una prima idea potrebbe essere la riga seguente (si ricorda che in ambiente GNU/Linux invocare awk è equivalente a chiamare gawk):
awk 'gsub(/\./,",");' Dati.csv > Nuovo.csv
dove viene utilizzata la funzione built-in gsub(r,c,v) che ad ogni occorrenza del pattern r, definito eventualmente da una espressione regolare tra caratteri slash / con metacaratteri quotati con backslash \, viene sostituita la stringa c nella variabile v. Nello specifico la sostituzione avverrà su tutti i record (le righe) del file: di default il record separator, la variabile d’ambiente RS, equivale al newline \n.
Con la riga riportata tutte le occorrenze del carattere punto “.” verranno sostituite dal carattere virgola “,” redirigendo l’output, carattere “>“, sul file Nuovo.csv. Non applicando la redirezione l’output verrebbe mostrato a schermo: in entrambi i casi il file originale non viene toccato/modificato. Se si provasse ad applicare il comando nel risultato si potrebbe notare come il primo record (prima riga) la scritta Umid.Relativa verrebbe cambiata in Umid,Relativa e questo non è risultato che si vuole. Allora occorre escludere la prima riga dalle “grinfie” di Awk e per farlo può essere utilizzata la riga:
awk 'NR!=1?gsub(/\./,","):"print";' Dati.csv > Nuovo.csv
Cosa è stato fatto? Come oramai noto Awk supporta i costrutti di controllo classici tra i quali l’if secondo la seguente sintassi:
if (espressione-condizionale)
{
Azione1
}
else
{
Azione2
}
ma supporta anche l’operatore ternario con la sintassi:
espressione-condizionale ? Azione1 : Azione2 ;
con funzionamento analogo all’if-else: se l’espressione condizionale è vera verrà eseguita Azione1 altrimenti Azione2. E con questa riga il primo punto è risolto.
Per risolvere il secondo obiettivo è sufficiente, con una seconda riga, richiamare di nuovo la stessa funzione: gsub(/\, /,”;”), tutto ciò che presenta una virgola “,” seguita da uno spazio bianco è da sostituire con il carattere “;” altrimenti si può adottare in forma compatta un’unica riga:
awk '{if (NR!=1) {gsub(/\, /,";");gsub(/\./,","); print} else print}' Dati.csv > Nuovo.csv
Se si vuole sovrascrivere il file (eseguire questa operazioni sempre sulla copia, mai sull’originale!) si può utilizzare:
awk '{gsub(/\, /,";");gsub(/\./,",");a[NR]=$0;}END{for (i=1;<=NR;i++){print a[i] > FILENAME;}}' Dati.csv
riga che risulterà più chiara tra breve, nel paragrafo Gli array in Awk.
NOTA: Se la formattazione del file originale dovesse cambiare, ad esempio in seguito a futuri adeguamenti del firmware che fornisce i valori indicati, allora le righe riportate, che possono far parte di uno script, non funzioneranno più a dovere! In questi frangenti è il caso che si venga avvisati in caso di cambi al fine di evitare grossolani errori con conseguenti risultati indecifrabili o, peggio, indurre in errate interpretazioni!
Una seconda applicazione
Convertiti i dati con separatori di colonna (campi) uniformi, si può pensare, ad esempio, di creare una tabella in HTML al fine di riportare i dati in un sito Web (o visualizzarli in un browser localmente), fermo restando che questo è sempre possibile con qualsiasi altro linguaggio (ad esempio Perl o Python).
Si possono ipotizzare migliaia di misure per un report (come in realtà avviene) e di avere un file di nome Dati.csv contenente le suddette misure. Una volta adattato il file in base a quanto detto in precedenza si avrà il file Nuovo.csv.
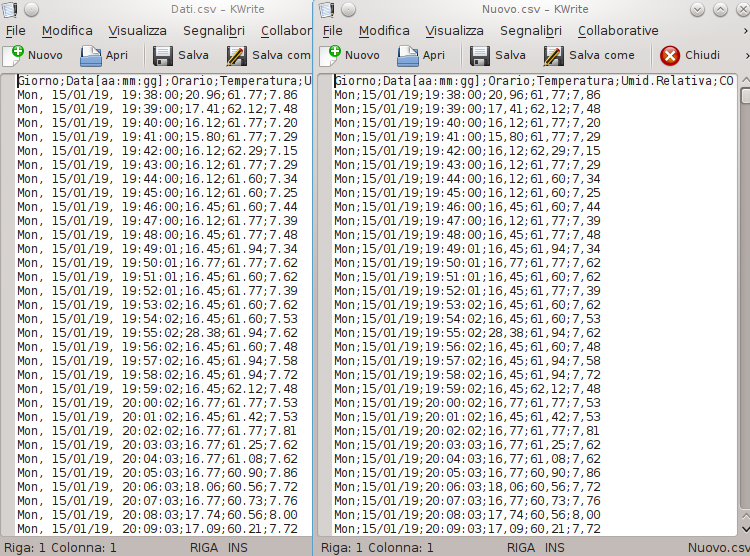
A sinistra i dati originali, a destra il file modificato
Per creare una tabella in HTML occorre ricordare come costruirle. Il tag da utilizzare è <table> e deve essere chiuso con il corrispondente </table>. All’interno della tabella si possono specificare le righe tra i tag <tr> e </tr> (table row) ed all’interno di esse occorre specificarne il contenuto, le celle con i tag <td> e </td> (table data). I tag <td> e <table> accettano diverse opzioni riguardo gli allineamenti (align e valign) così come il colore di sfondo (bgcolor) e di bordo (bordecolor).
NOTA: con il rilascio di HTML5 diverse opzioni sono state deprecate.
Dopo il breve promemoria, in basso viene riportato il file che trasforma il report CSV in una tabella HTML. Presenti anche tutti i commenti del caso.
#!/usr/bin/gawk -f
# Lo shebang riportato in prima riga ci permette
# di lanciare questo sorgente, dopo averlo reso
# eseguibile con il comando:
#
# chmod +x CreaTabella.awk
#
# come:
#
# ./CreaTabella.awk Nuovo.csv > dati.html
#
# Questo sorgente può essere diviso in 4 regole.
#
# Prima regola con il BEGIN: l'azione associata
# viene eseguita prima di iniziare l'elaborazione
# del file. Nello specifico viene aperto il tag
# <table> e impostate alcune opzioni. La tipica
# intestazione di un file HTML non viene presa
# in considerazione volutamente. Ognuno potrà
# aggiungere l'intestazione con il titolo più
# adatto.
BEGIN {
FS =";";
printf "%s%s%s",
"<table cellpadding=\"1pt\" border=\"3pt\" ",
"cellspacing=\"0pt\" bgcolor=\"#ffffff\" ",
"bordercolor=\"#000000\">\n";
}
# Seconda regola nella modalità: pattern {azione}.
# Il pattern, ovvero i dati da cercare dal file di
# ingresso, è la condizione NR==1 ovvero al primo
# record (sinonimo di riga, ricordiamo che la
# variabile d'ambiente NR ha il valore di default
# del newline "\n") del file in ingresso associamo
# l'intestazione della tabella assegnandole anche
# un colore di sfondo per distinguerla dalle righe
# successive nelle quali abbiamo orario e valori
# dei sensori. Le tabulazioni orizzontali presenti,
# ovvero la sequenza di caratteri "\t", servono
# ad indentare il codice HTML per una più facile
# leggibilità, ma non obbligatoria in questo
# metalinguaggio a differenza di altri come il
# Python.
(NR==1){
printf "\t<tr bgcolor=\"#dfdfdf\">\n"
# NF è la variabile d'ambiente Number of Fields ovvero
# il separatore di campo che nel nostro caso abbiamo
# impostato al carattere ";". Con il ciclo di for che
# segue andiamo a scandire ogni singolo campo della
# prima riga e lo assegniamo come valore ad ogni
# cella centrandolo previo utilizzo dei tag:
# <center> e </center> per la chiusura.
for( i=1; i<=NF; i++ )
{
printf "\t\t<td><center>%s</center></td>\n", $i;
}
printf "\t</tr>\n"
}
# Terza regola: medesima modalità "pattern {azione}".
# Per ogni valore della variabile NF maggiore di 1
# nonché della variabile NR maggiore di 1, ovvero
# intestazione esclusa, creiamo le celle e inseriamo
# i relativi valori. I primi 3 campi, dal giorno
# della settimana fino all'orario, vengono allineati
# a sinistra, tutti gli altri, ovvero i valori delle
# misure, a destra.
(NF>0 && NR>1){
printf "\t<tr>\n"
for( i=1; i<=NF; i++ )
{
if ( i<=3 ) {
printf "\t\t<td align=left>%s</td>\n", $i;
} else {
printf "\t\t<td align=right>%s</td>\n", $i;
}
}
printf "\t</tr>\n"
}
# Quarta regola: eseguita per aggiungere il tag di
# chiusura della tabella. Il pattern dopo END viene
# eseguito solo dopo che tutte le righe del file
# in ingresso sono state elaborate.
END {
printf "</table>\n";
}
Un programma Awk può essere invocato in diversi modi, ad esempio da riga di comando indicando direttamente il nome se nel sorgente Awk è riportato lo shebang #!/usr/bin/awk -f in prima riga, dall’interno di uno script bash oppure utilizzando l’opzione -f e specificando il file dal quale leggerlo. Fatta questa premessa dopo aver reso uniforme il file csv si può lanciare il comando:
awk -f CreaTabella.awk Nuovo.csv > dati.html
il quale creerà il file dati.html da lanciare in un browser (figura in basso). Volendo valutare in linea di massima l’esecuzione del comando su un file con un importante numero di dati, si può anteporre il comando time ai comandi precedenti e il cui output potrà essere interpretato approfondendo dal manuale on line (man time).
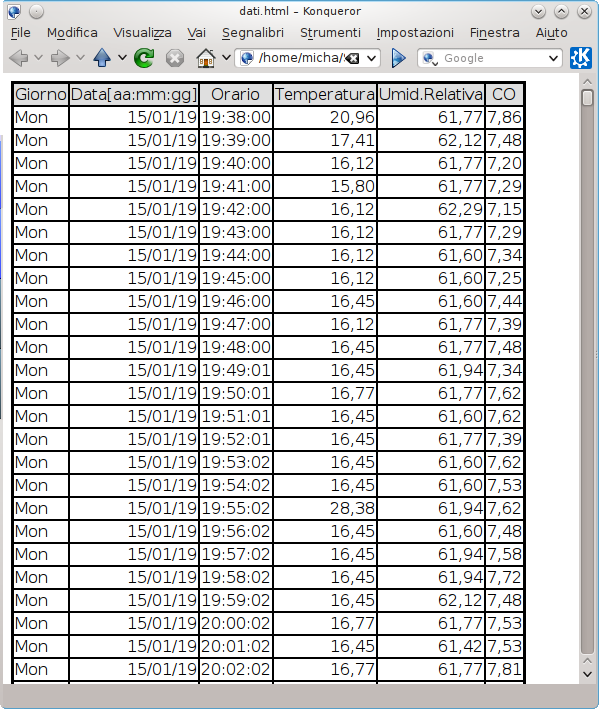
Risultato della tabella HTML
Gli array in Awk
In un comando precedente è stato utilizzato il concetto di array, uno degli argomenti importanti ancora rimasti in sospeso. Cos’è un array?
Si immagini un vettore riga contenente n elementi: {1,2,3,…,n}, questo è un esempio di array monodimensionale (o unidimensionale). Una sorta di variabile contenente più valori e che in altri linguaggi devono essere obbligatoriamente dello stesso tipo e preventivamente dichiarati.
Gli elementi dell’array sono distinguibili dall’indice che in genere è un numero che inizia da 0 per il primo elemento, assume valore 1 per il secondo e così a seguire, ma può essere definito anche da una stringa definendo così gli array associativi noti, ad esempio, a chi conosce il PHP e/o Javascript.
Un array associativo ha un indice che non è un numero intero ma è una stringa. Si possono così creare strutture dati molto efficienti alle quali è possibile associare valori a chiavi arbitrarie. Ad esempio, la riga:
{for (i=1; i<=NF; i++) campo[$i]++}
l’elemento dell’array associativo campo[termine1] verrà incrementato di un’unità, analogamente campo[termine2] etc. Se incontra di nuovo campo[termine1] viene nuovamente incrementato di 1 unità e così a seguire: con 3-4 righe di codice è possibile fare, ad esempio, un conta parole nel contenuto di un file di testo!
In Awk, analogamente alle variabili, non c’è necessità di dichiarare l’array tanto meno specificarne le dimensioni prima dell’uso, procedura che invece è obbligatoria, ad esempio, nel linguaggio C.
Si accede ad un elemento dell’array tramite nome_array[indice] (il riferimento ad un valore non esistente ritorna la stringa nulla), così come l’assegnamento può essere effettuato con array[indice]=valore.
Fatta questa premessa è possibile procedere con il comando rimasto in sospeso. Si noti l’uso di due regole: la prima applicata a tutti i record del file per il raggiungimento dell’obiettivo con l’aggiunta di a[NR]=$0 che rientra nella definizione di assegnamento del valore di un array, dove NR è la variabile d’ambiente Number of Record ovvero il numero di righe lette e $0 è la variabile d’ambiente che indica l’intero record, cioè l’insieme di tutti i campi che costituiscono quella riga (record). In sostanza l’array conterrà tutte le righe del file: ogni elemento dell’array, identificato da un indice numerico, equivarrà ad una riga del file.
La seconda regola inizia con END e viene lanciata dopo che tutte le righe del file sono state lette. Nello specifico con un ciclo for vengono scansionate tutte le righe e per ognuna di essa viene fatta la stampa rediretta sul file FILENAME la variabile d’ambiente che indica il nome del file corrente in ingresso (si rimanda al manuale online man gawk per gli approfondimenti e le osservazioni su questa variabile).
Matematica e Awk
I dati forniti da una qualsiasi misura possono essere sottoposti a diverse interpretazioni. Awk, come altri linguaggi, ha una serie di operatori e funzioni built-in dedicati alle operazioni aritmetiche e matematiche, dalle elaborazioni più elementari a quelle più complesse. Va ricordato che numeri in Awk sono di default espressi sempre in floating point il che significa che l’operatore di divisione “/” fornisce un risultato sempre in floating point e non arrotondato ad un intero come avviene ad esempio nel linguaggio C. Premesso questo nel seguito è riportato un esempio applicativo: ad esempio dal gruppo di righe precedenti si potrebbe essere interessati alla valutazione della somma totale di una colonna (ad esempio la temperatura) così come alla valutazione del valore medio e/o sapere quando è avvenuto il valore massimo (e/o il valore minimo).
#!/usr/bin/awk -f
{
FS=";";
gsub(/,/,".",$4)
somma += $4
if (massimo < $4)
{
massimo=$4
data=$2
ora=$3
}
}
END { if (NR>0) printf "Somma pari a %5.2f su un totale di righe %d. La media dei valori è pari a %5.3f.\n",somma,(NR-1),somma/(NR-1); \
printf "Il valore massimo di %3.2f si è avuto il %s alle ore %s.\n",massimo,data,ora}
Dopo aver copiato le righe in un file, ad esempio, di nome Media.awk, salvare il file nella cartella dove è presente il file Nuovo.csv , renderlo eseguibile con chmod +x Media.awk quindi impartire il comando ./Media.awk Nuovo.csv per avere a schermo i valori ai quali si è interessati (immagine in basso).
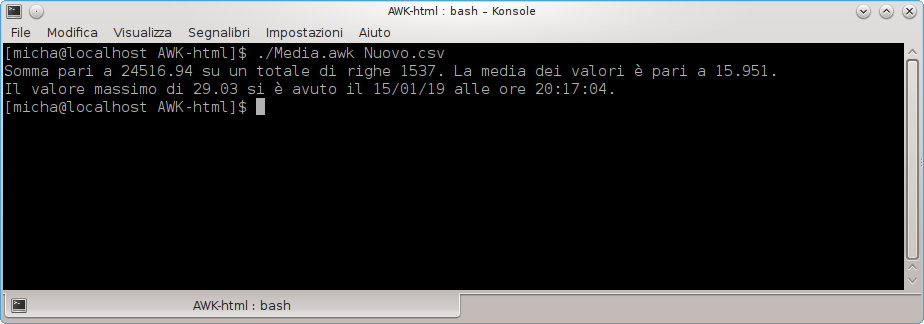
Risultato del valore medio e del valore massimo
Due note a conclusione di questo paragrafo: si applica la funzione gsub() per riconvertire solo il campo 4 ad una rappresentazione decimale con il punto per evitare complicazioni sulle impostazioni delle variabili d’ambiente del sistema operativo. La seconda nota riguarda il backslash presente sulla riga dell’END: indica all’interprete che quella riga continua.
Quello riportato è solo un semplice esempio applicativo sul come calcolare una media utilizzando Awk, si possono infatti realizzare programmi per l’interpolazione lineare e/o polinomiale al fine di conoscere, ad esempio, i valori dei dati tra una misura e un’altra: è questo il modo con il quale un foglio di calcolo raccorda i valori nel creare un grafico.
Immagini con Awk?! Perché no!
Esatto, qualche semplice immagine con Awk e integrazione con la shell bash. Ma com’è possibile realizzare un’immagine utilizzando un linguaggio nato principalmente per processare del testo?
La risposta, così come la comprensione, diventa immediata ricordando che un’immagine è caratterizzata da un insieme di punti (pixel) e ogni punto ha una propria sfumatura di colore a seconda di ciò che deve rappresentare nel contesto in cui è inserito.
Il modo più semplice per capire il concetto è riferirsi al formato RGB acronimo di Red-Green-Blue ad indicare i tre colori rosso, verde e blu. Ogni pixel si porta dietro un’informazione tipicamente legata al colore che dovrà rappresentare.
La più piccola informazione che può contenere è pari a 1 bit: punto bianco (valore 1) o punto di colore nero (valore 0). A seguire abbiamo che il singolo punto può portare un’informazione a 8 bit che in decimale corrisponde a 256 valori (2^8) compresi tra 0 e 255: 0 pixel nero, 255 pixel bianco e, in una scala lineare, il 127 indica il 50% di livello di grigio.
Lo step successivo, di interesse in questo caso, vede il pixel portarsi un’informazione di ben 24 bit suddivisi in 8 bit per il livello del Rosso, 8 bit per il livello del Verde e 8 bit per il livello del Blu. Questo significa che ogni canale RGB può assumere 256 valori, da 0 a 255: dire che il canale del rosso è pari a 0 equivale ad affermare che il rosso è stato “spento” e via via che ci spostiamo verso il valore 255 si passa da un rosso molto scuro ad un rosso vivo secondo le varie tonalità. Analoghe considerazioni per il verde e il blu. Poiché ogni canale può assumere 256 valori differenti e poiché si hanno 3 canali per pixel, ecco che per ogni pixel è possibile rappresentare con 24 bit un totale di 256^3=16.777.216 colori! Premesso questo se vi venisse detto che il valore di ogni singolo byte (8 bit) di canale definisce l’indice di un array ecco che tutti i valori dell’array rappresentano una tavolozza (palette) di colori relativi a quel canale che combinato con gli altri due rimanenti forniscono il totale di colori visto poco sopra: allora gli indici combinati delle tre tavolozze ci danno il colore di un pixel! L’insieme di decine, centinaia e migliaia di indici a queste tavolozze creano l’immagine!
Dopo la breve premessa il prossimo obiettivo sarà creare con Awk l’immagine della bandiera Italiana. Come fare? Di seguito verranno riportati due file, uno in Awk (e.g. Bandiera.awk) e uno script shell (Bandiera.sh),
BEGIN {
# Nella prime 3 righe utilizziamo la funzione built-in "split(s,A,sep)"
# la quale non fa altro che spezzare la stringa "s" in campi separati
# il cui separatore è indicato nel campo "sep": i valori ottenuti
# vengono memorizzati nell'array A.
# Quindi le 3 righe che seguono creano 3 array (tavolozze) di colori
# caratterizzate da 3 valori per il rosso e 3 per il verde e il blu.
split("27,255,255",Rosso,",");
split("132,255,0",Verde,",");
split("0,255,0",Blu,",");
# Variabile utilizzata per memorizzare il nome del file in uscita.
fileppm="Bandiera.ppm";
# Scriviamo sul file d'uscita l'header obbligatorio per il rispetto
# dello standard del formato ppm (molto semplice, ad esempio, rispetto
# al formato bmp. E' caratterizzato da 4 campi:
#
# - P3 - primo campo - definisce l'immagine del formato che
# nello specifico indica immagine PPM RGB a 24 bit con codifica ASCII.
# Per il formato PPM si ha anche il valore P6 ad indicare il formato
# di codifica binaria;
#
# - Il secondo e terzo campo indicano rispettivamente larghezza e
# altezza in pixel dell'immagine;
#
# - Il quarto campo indica il massimo valore che possono assumere i
# colori: nello specifico 255, pertanto qualsiasi valore compreso
# nel range 0-255 quindi si possono sfruttare tutti gli oltre 16
# milioni di colori.
#
printf("P3\n100 180\n255\n") > fileppm;
# Nel ciclo di for che segue utilizziamo la funzione built-in
# length() la quale restituisce la lunghezza del suo parametro
# l'array Rosso nel nostro esempio. Allora che funzione ha il
# for? Semplice, scandisce la lunghezza dell'array Rosso (che
# è uguale all'array Verde e all'arry Blu).
for (k=1; k<=length(Rosso); k++)
{
# Entrati nel primo for troviamo subito un altro for. Il
# nostro obiettivo è creare una immagine della bandiera
# da 180 pixel in larghezza e 100 in altezza (un totale
# di 18.000 pixel) divisa in tre bande di colori di
# larghezza uguale: avendo 180 pixel di larghezza allora
# ogni banda sarà 60 pixel in larghezza e 100 in altezza
# per un totale di 6000 pixel per fascia di colore.
for (i=1; i<=6000; i++)
{
# Ma chi ci da il colore da disegnare? Le tavolozze di
# colori che abbiamo creato nelle prime 3 righe. Ad
# esempio per k=1 Rosso[1]=27, Verde[1]=132 e Blu[1]=0
# ovvero una tonalità del verde che più si avvicina
# al colore di nostro interesse. Questo valore ripetuto
# per 6000 volte ci costruisce la banda verde per poi
# passare a k=2 per il bianco con altri 6000 pixel e a
# finire con il blu. Osserviamo che in realtà noi creiamo
# dapprima la bandiera in verticale semplicemente perché
# è più semplice in quanto i pixel partono dal punto in
# alto a sinistra per proseguire verso destra per passare
# poi alla seconda riga e così via a seguire.
printf("%3i %3i %3i\n",Rosso[k],Verde[k],Blu[k]) > fileppm;
}
}
# Chiudiamo il file
close(outfile);
}
Subito in basso invece lo script shell che richiamerà il file Awk.
#!/usr/bin/bash # Generiamo l'immagine PPM della bandiera mediante Awk awk -f ./Bandiera.awk # Possiamo richiamare il file Awk anche riportando solo # il nome, ad esempio: # # ./Bandiera.awk # # a patto che nella prima riga del file Awk venga inserito # lo shebang: #!/usr/bin/awk -f # # E' necessario che risulti installato ImageMagick # (https://imagemagick.org) poiché utilizziamo lo # strumento convert per ruotare e convertire # l'immagine da ppm a png. I parametri riportati # nella variabile conversione indicano nell'ordine: # # -quality : il livello di compressione per i # formati jpeg, miff e png. # # -rotate : Ruota l'immagine. # conversione="convert -quality 90 -rotate 270" # Indichaimo a convert il nome del file in ingresso ppm # e il nome del file in uscita png. conversione=$conversione" Bandiera.ppm Bandiera.png" # L'opzione -c indica alla shell di leggere i comandi da # stringa. Se dopo la stringa vi sono degli argoemnti # verranno assegnati alle variabili posizionali a partire # dalla variabile $0 e a seguire ($1, $2 etc). # L'eseguibile sh è un link simbolico all'eseguibile bash # in /usr/bin. /usr/bin/sh -c "$conversione"
Per le prove è sufficiente copiare le righe in due file con i nomi riportati, renderli entrambi eseguibili e lanciarli da una shell il comando ./Bandiera.sh per trovare l’immagine in ppm (Portable Pix Map) e in png (Portable Network Graphics).
Il risultato è visibile nell’immagine in basso all’interno di un editor esadecimale wxHexEditor con il quale è stata aperta l’immagine in formato ppm: si noti l’intestazione standard del formato ppm seguito dai valori dei tre canali RGB per disegnare il verde, il bianco e il rosso. Per interpretare i valori in esadecimale si può far uso di una tabella ASCII.
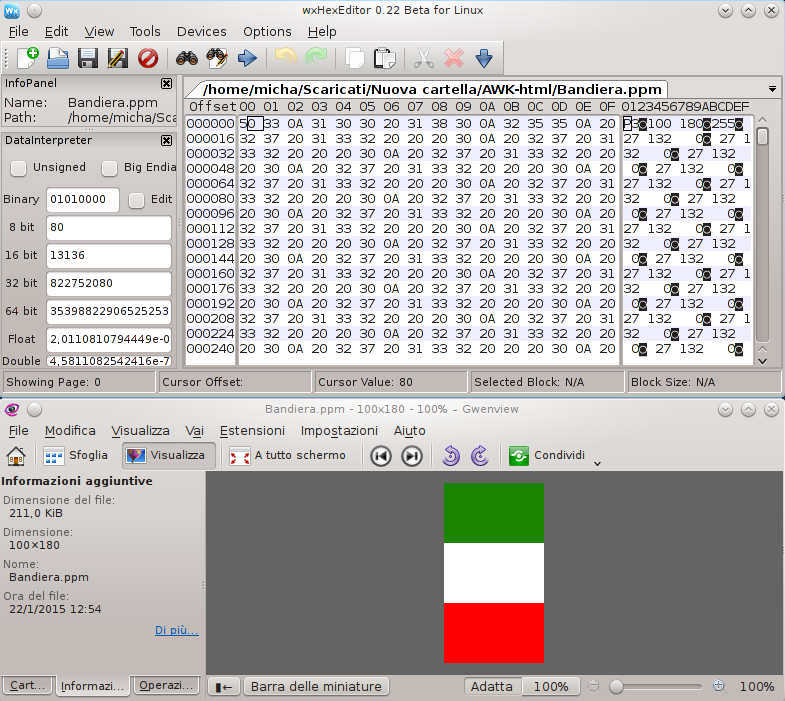
In basso la nostra bandiera prima della rotazione e conversione in png, in alto il file in formato ppm in un editor esadecimale
Nell’immagine è visibile un editor esadecimale con il quale è stata aperta l’immagine in formato ppm: si può notare l’intestazione standard del formato ppm seguito dai valori dei tre canali RGB per disegnare il verde, il bianco e il rosso.
Bibliografia
A chi è interessato all’approfondimento di questo linguaggio di programmazione va ricordato che, oltre al manuale online (man gawk), sono stati scritti alcuni libri tra i quali si vogliono ricordare
- Effective Awk programming di Arnold Robbins pubblicato da O’Reilly;
- Sed & Awk di Dale Dougherty e Arnold Robbins pubblicato da O’Reilly;
- Lo storico The Awk programming language scritto dagli stessi creatori di Awk ovvero Alfred Aho, Brian Kernighan e Peter Weinberger pubblicato da Addison-Wesley.